
[CS224N] 3. Natural Language Processing with Deep Learning
1. NER
NER은 Named Entity Recognition의 약자로, 단어를 찾아 분류하고 카테고리화시키는 작업이다. 다음을 예시로 들어보자.

여기서 Paris라는 단어를 단어장에서 찾으면 프랑스의 파리가 찾아지지만, 본문에서는 사람 이름으로 사용되었다. 이렇듯, NER을 정확하게 파악하기 위해서는 항상 context를 고려해야 한다.
이걸 Neural Network으로 어떻게 할 수 있을까?
Simple NER: Window classification using binary logistic classfier
먼저 아이디어는 word vectors를 이용해서 word vectors로 이루어진 context window를 만들고, 그걸 neural network layer에 넣고, logistic classifier를 통과시켜 해당 단어가 무엇을 나타내는지 분석한다. 예시로, 다음 문장을 생각해 보자.
이 문장들에서 Paris에 대해서 알고 싶으면, 단어 'Paris'를 기준으로 +-2 만큼 크기의 단어들을 가져와 window를 만든다.
window들의 각 단어에 대해, word2vec이나 Glove 등을 사용해서 단어를 word vector들로 만들고, 이 벡터들을 classifier에 전달한다. 그럼 결과로, 해당 단어가 위치 정보를 나타낼 확률을 가질 수 있다. 또 다른 classifier를 통과하면 해당 단어가 사람의 이름인지 판단할 수도 있다. (이는 둘 다 binary logistic classifier를 활용한 예시이다.) 과정은 다음과 같다:
만약 D dimention word vector들이 있다면, input(x)은 5D dimention의 window가 된다. 이를 neural network의 layer에 넣으면, 해당 layer에서는 vector(x)를 matrix(W)와 곱하고, bias vector(b)를 더해 softmax와 같은 비선형성(f)에 넣는다. 그럼 결과로 hidden vector(h)를 얻게 되는데, 이는 훨씬 작은 차원이 될 수 있다. 이후, 해당 hidden vector와 추가적인 vector(u)의 dot product를 수행하여 하나의 실제 숫자 실수 (s)를 얻게 된다. 이후, 해당 숫자 s를 logistic classifier에 넣어 결과로 단어의 예측 확률을 반환한다.
2. Stochastic Gradient Descent
위의 신경망을 계산하기 위해 1) 손으로 직접 SGD를 적용하는 방법과, 2) 시스템으로 SGD를 적용하는 방법을 나누어 설명한다.
각각에 대해 설명하기 전, 먼저 SGD가 어떤 작업인지 알아보자.
모델의 손실을 줄이고 파라미터를 잘 업데이트하기 위해, 본 강의에서는 Stochastic Gradient Descent 방법을 사용한다.
그렇다면 SGD와 Gradient Descent와의 차이점은 무엇인지 궁금해서 찾아보게 되었다.
먼저 Gradient Descent는 최소 loss를 찾기 위해 한 지점에서 기울기를 기반으로 지점을 옮겨나가는 방식이다.
그러나, 이 방법에서는 경사를 계산하는 데 사용되는 예의 집합, batch 가 모든 data이다. 즉, dataset에 수십, 수백억 개의 데이터가 쌓일 수도 있다는 뜻이다. 이렇게 큰 batch를 사용하면 계산을 위해 너무 많은 시간을 사용하게 된다는 단점이 있다.
이것을 보완하기 위해 나온 방법이 SGD인데, 이는 한 번의 반복당 단 한 개의 batch만을 무작위로 뽑아 사용하는 방식이다. '무작위'로 하나의 데이터만을 선택하기 때문에, 노이즈가 증가한다는 단점이 있다.
그래서 SGD를 보완하기 위해 나온 방법이 Mini Batch SGD인데, 말 그대로 10~1000개 정도의 batch를 사용하는 방식이다. 이 방법이 훨씬 안정적이면서 효율적이라고 한다.
이제 두 가지 방법으로 gradient를 계산하는 방법에 대해 알아보자.
1. Computing Gradients by Hand
먼저, 손으로 계산해 보는 방법이다. 이는 vectorized gradients를 계산하는데, 이는 어떤 항목이 변했을 때, 그 항목의 변화량이 최종 결과물에 얼마만큼의 변화를 주는가에 대해서 알아본다.
먼저 f(x) = f(x1, x2,... , xn)이라고 하자. 그럼 df/dx는 partial derivatives에 대한 vector 표현이고, 다음과 같이 나타낼 수 있다:
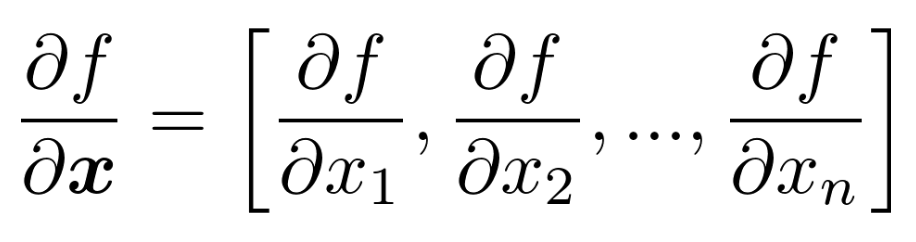
이후, Jacobian Matrix를 도입한다. 먼저, n개의 input으로 m개의 output을 만드는 함수 f(x)가 있다고 가정하자. 이는 다음과 같이 정의된다: f(x) = [f1(x1, x2, x3,..., xn),..., fn(x1, x2, x3,..., xn)]
여기서 df/dx를 구하면, 다음과 같이 m*n matrix로 나타낼 수 있는데, 이것을 Jacobian matrix라고 한다.

그렇다면, 다음 예시 문제를 생각해 보자.
f가 softmax 함수일 경우, h=f(z), z=Wx+b 를 만족시키는 h, f, z, W, b 가 있다고 하자. (h, z는 둘 다 n차원이다.)
Q. 여기서 dh/dz를 어떻게 구할까?
A. 답은 다음과 같다:

당연히, j 요소에 대한 i 요소의 편미분 값을 구하는데, j와 관련이 없으면 그 값은 0이 될 것이다. 그러므로, i와 j가 같을 때만 값이 나오고, 그 결과로 jacobian matrix는 대각행렬이 된다.
다른 jacobain matrix의 예시로 다음과 같은 것들이 있다:

마지막은 내적곱에 대한 jacobian인데, 이는 뒤 요소의 전치된 행렬이 결과가 된다.
Back to NeuralNet
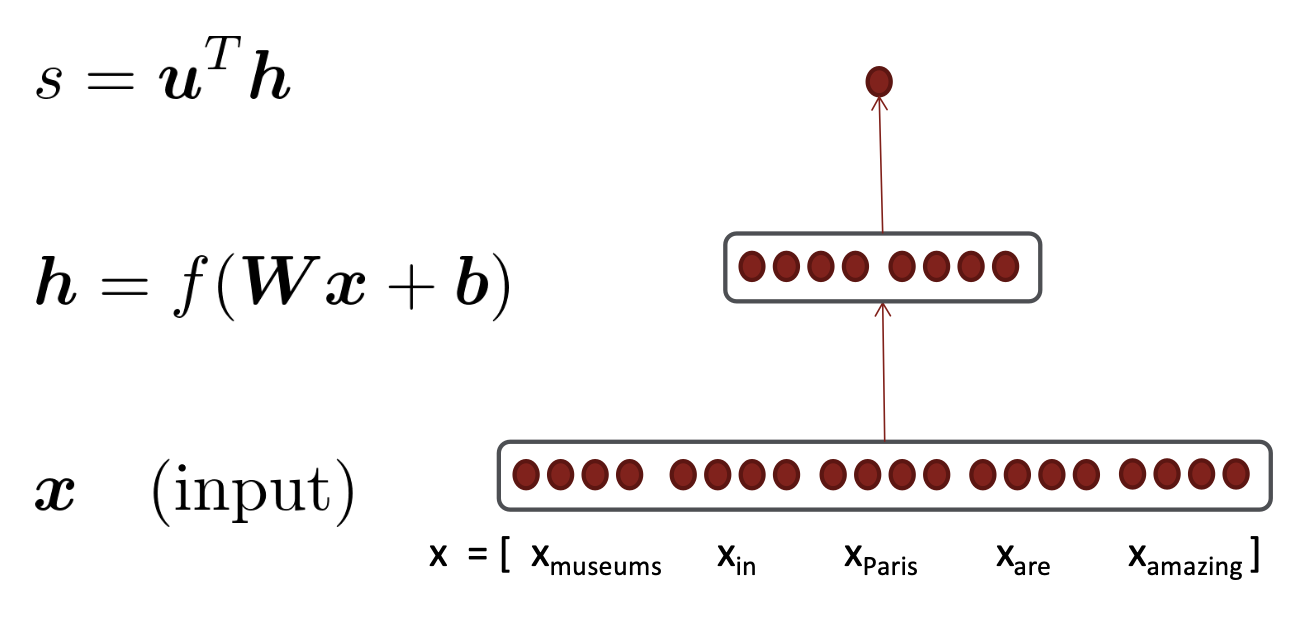
원래는 loss J를 줄이는 것이 목적이지만, 간단하게 score s의 gradient를 계산하는 것으로 대신해 보자. 그럼 구해야 할 것은 ds/db가 된다. 주어진 식들과 Chain rule을 적용해서 계산한 결과는 다음과 같다:

마지막의 흰색 동그라미는 Hadamard product를 뜻한다.
Reusing Computation
이제 ds/db를 구했으니, ds/dW를 구하려고 한다고 가정하자. 이걸 Chain Rule을 사용해서 나타내면 다음과 같다:
ds/dW = ds/dh * dh/dz * dz/dW
근데, 이는 ds/db를 구하는 위 사진의 식과 앞 2 요소가 완전히 같다. 따라서, duplicated computation을 피해보도록 하겠다.

파란색 부분은 delta로 나타내면, 아래와 같이 식들을 다시 정리할 수 있다.
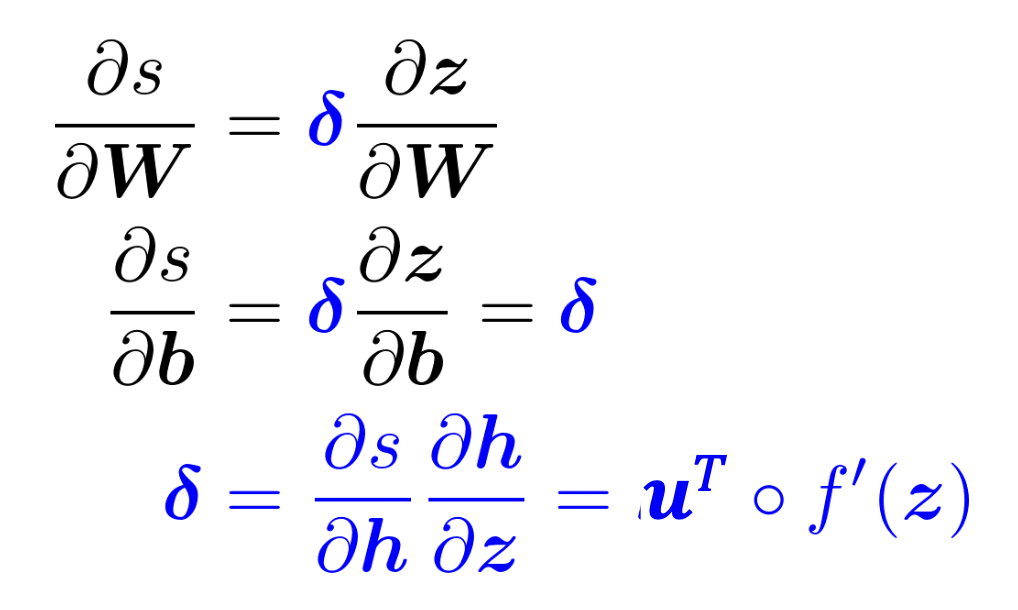
이러면, 복잡한 똑같은 계산을 두 번 하는 것을 방지할 수 있는데, 여기서의 delta를 local error signal이라고 한다.
Output Shape - Shape Convention
원래의 ds/dW는 W와 같은 크기를 가져야 parameter를 업데이트할 수 있다.
그럼, 계산을 통해 생성된 matrix의 모양을 보자. s는 하나의 score이어야 하므로, output은 1차원이 되어야 하므로, ds/dW는 1x(nm) 차원이 된다. 이는 원래 W와의 차원 크기가 맞지 않으며, 이 때문에 SGD를 계산하기 어렵다.
그러므로, Shape Convention을 통해 1x(nm)을 nxm 형태로 바꾸어야 한다. 바뀐 ds/dW는 다음과 같다:

그럼 결론적으로 ds/dW는 다음과 같이 표현된다.

이때, delta를 구하면 우리가 원하는 값을 구할 수 있다. 또, z = Wx + b 이므로 dz/dW는 x가 되어야 하는데, 정작 delta와 x를 계산한 것의 결과는 다음과 같다:
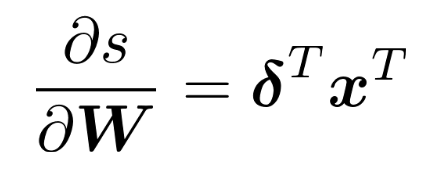
Why Transposes?
왜 전치가 일어나는 것일까?
사실 이전과 비슷하게 shape convention으로 dimension을 맞추기 위해서이다. 다음 사진을 보면 이해가 될 것이다.

따라서, Jacobian Matrix가 수학적으로는 좋지만, SGD에 쓰기 위해서는 shape convention이 필수적이다.
2. Backpropagation
그럼 위의 과정들을 소프트웨어적으로 구현해 보자.
먼저 Backpropagation 방식은 higher layer의 derivatives를 재사용하는 것인데, Computation Graph를 먼저 살펴보자.

위의 그림과 같이, 앞으로 순차적인 파를 보내는 것을 Forward Propagation, 순전파라고 한다.
그렇다면 backpropagation은 당연히 뒤의 파를 앞으로 보내주는 역방향이 되겠고, 리는 다음과 같이 나타낼 수 있다.
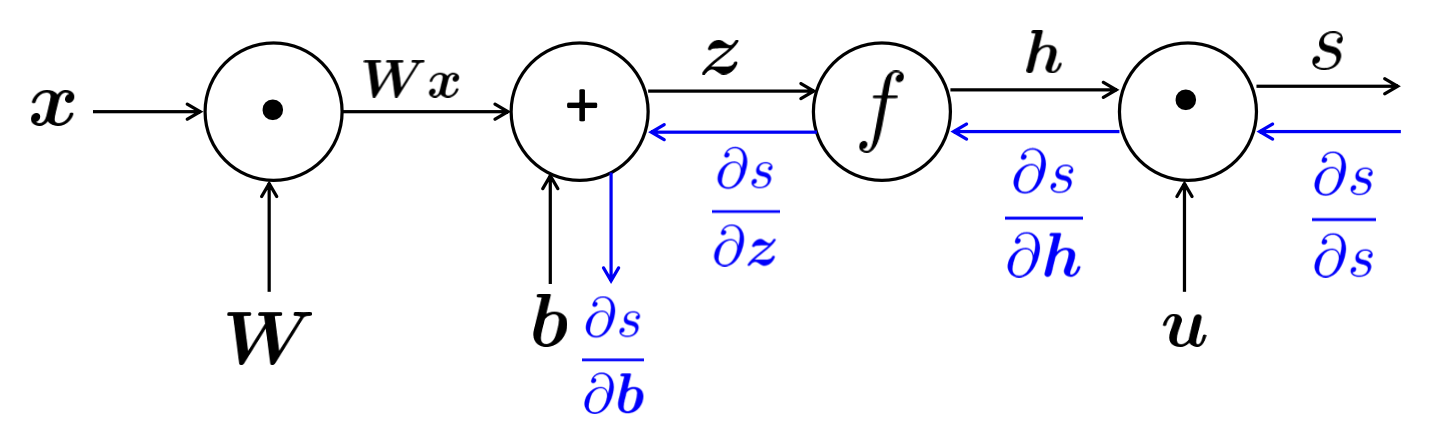
여기서 보내주는 파는, gradients를 보내주는 것이다. 이로 인해 parameter들이 업데이트된다.
그렇다면 이 과정을 어떻게 효율적으로 진행할 수 있을지가 관건이 되겠다.
Backpropagation: Single Node
먼저 이론을 더 자세하게 알기 위해 single node 형태를 살펴보자.
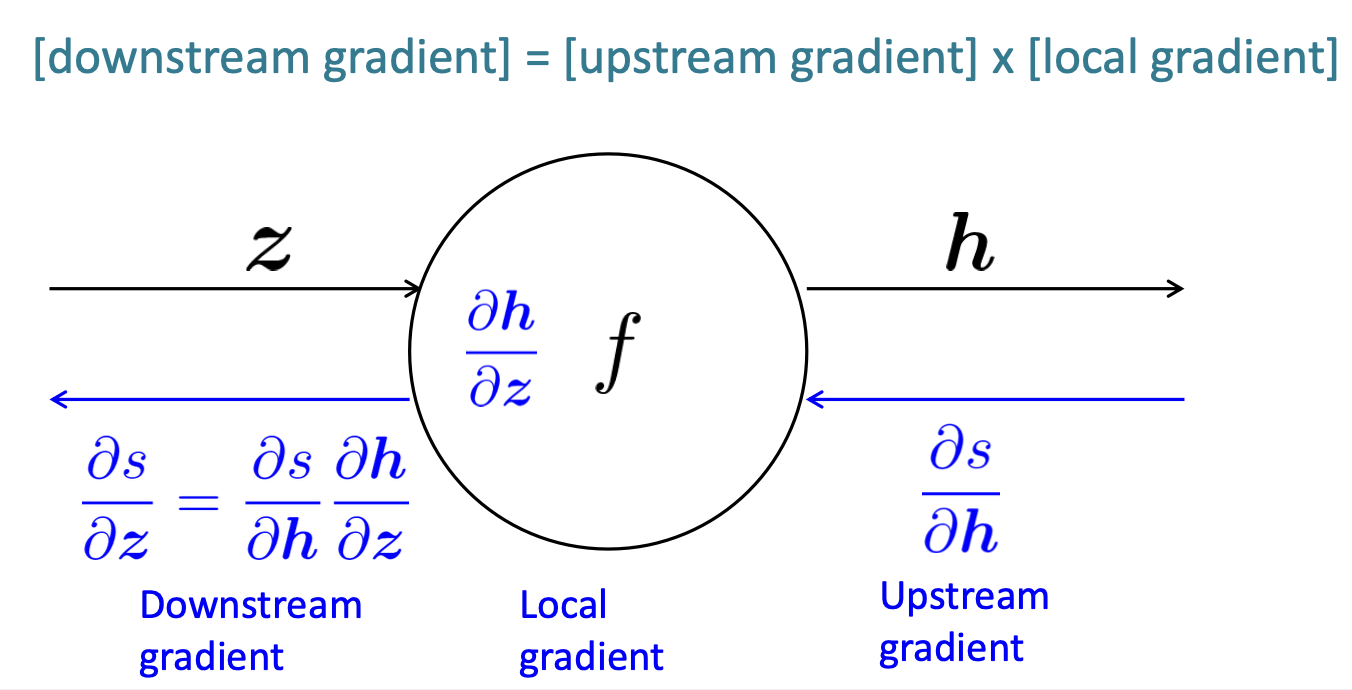
먼저, 위에서 내려오는 역전파를 upstream gradient, node에서 계산할 수 있는 gradient를 Local gradient, 계산되어 아래로 내려지는 gradient를 Downstream gradient라고 하자. 그렇다면, backpropagation은 기본적으로 사진 속 맨 위 공식을 만족하게 된다. 공식은 다음과 같다:
[Downstream Gradient] = [Upstream Gradient] * [Local Gradient]
계산 시 Chain rule을 적용하여 사진 속 왼쪽 하단에 보는 것처럼 편리하게 계산할 수 있다.
Example
그럼 간단한 예시를 들어 보자.
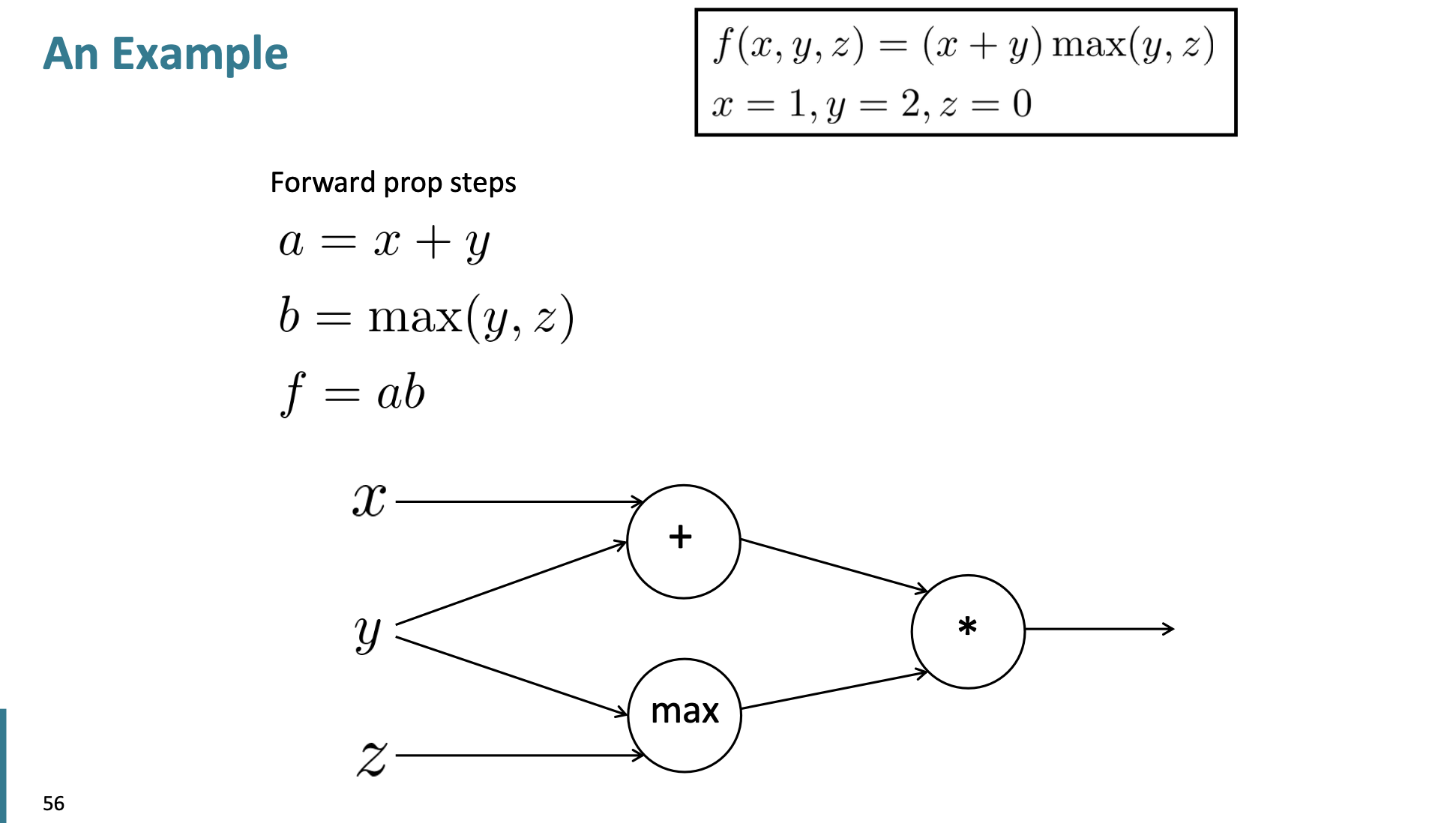
이런 식을 만족하는 f, a, b, x, y, z가 있다고 했을 때, 각 x, y, z가 f에 얼마만큼의 영향을 주는지 알아보자.

먼저 각각의 local gradient를 계산해 놓고, chain rule을 통해 역전파를 계속 앞으로 진행시키면 파란색 숫자가 '영향을 주는 정도'가 된다.
그리고 y의 경우에는 2갈래로 나누어지기 때문에, 이러한 경우에는 더한다.
Node Intuitions
또, 노드별 특징이 있다:
1. +노드는 upstream gradient를 각각 분배한다. 위에서 x와 y에게 2가 그대로 전달됐음을 볼 수 있다.
2. max 노드는 큰 값에서 upstream gradient를 전달한다. 위에서 3이 (y, z) 중 큰 y에게 전달됐음을 볼 수 있다.
3. * 노드는 순전파로 온 값을 바꾸어서 반영한다. *에게 전달된 *의 3과 max의 2가 역전파에서는 서로 뒤바뀌었음을 볼 수 있다.
Efficiency

앞서 설명했던 delta의 등장처럼, 당연히 소프트웨어적으로 계산 시에도 프로그램 속도와 효율성을 위해 같은 계산은 피해야 한다. 그러므로, 공통된 부분에 대한 계산은 최대한 줄일 수 있도록 공통된 부분을 잘 파악한다.
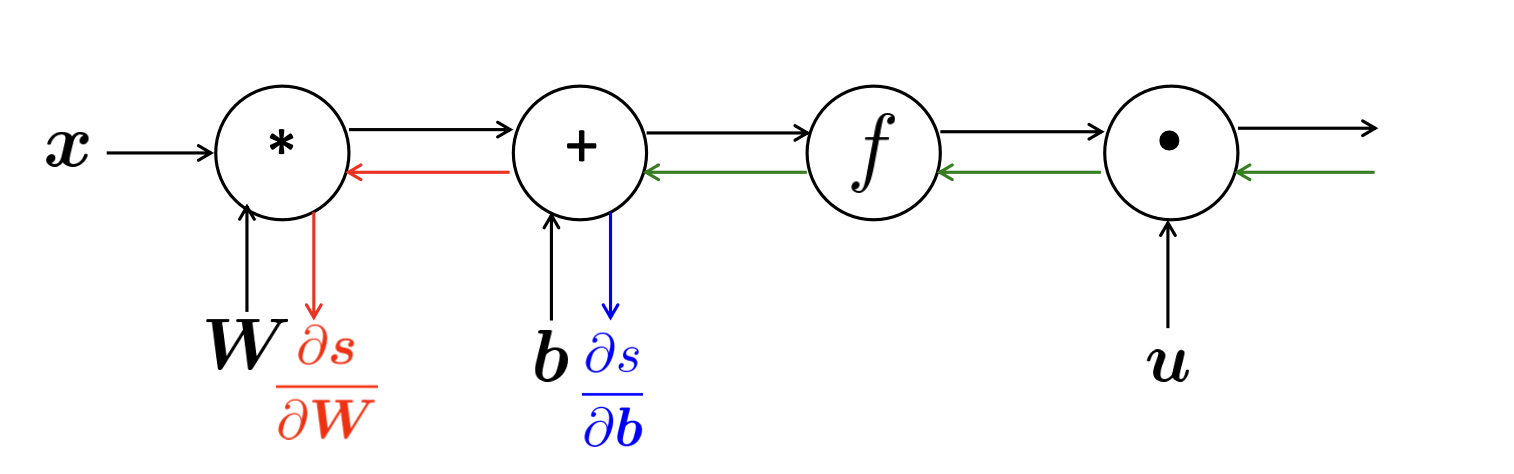
3. Pytorch code examples
사실 위의 과정들은 pytorch나 tensorflow등의 프레임워크에서 코드로 모두 제공해 주기 때문에, 코드만 적재적소에 잘 맞게 쓰면 된다. 예시로 다음 코드를 보면,
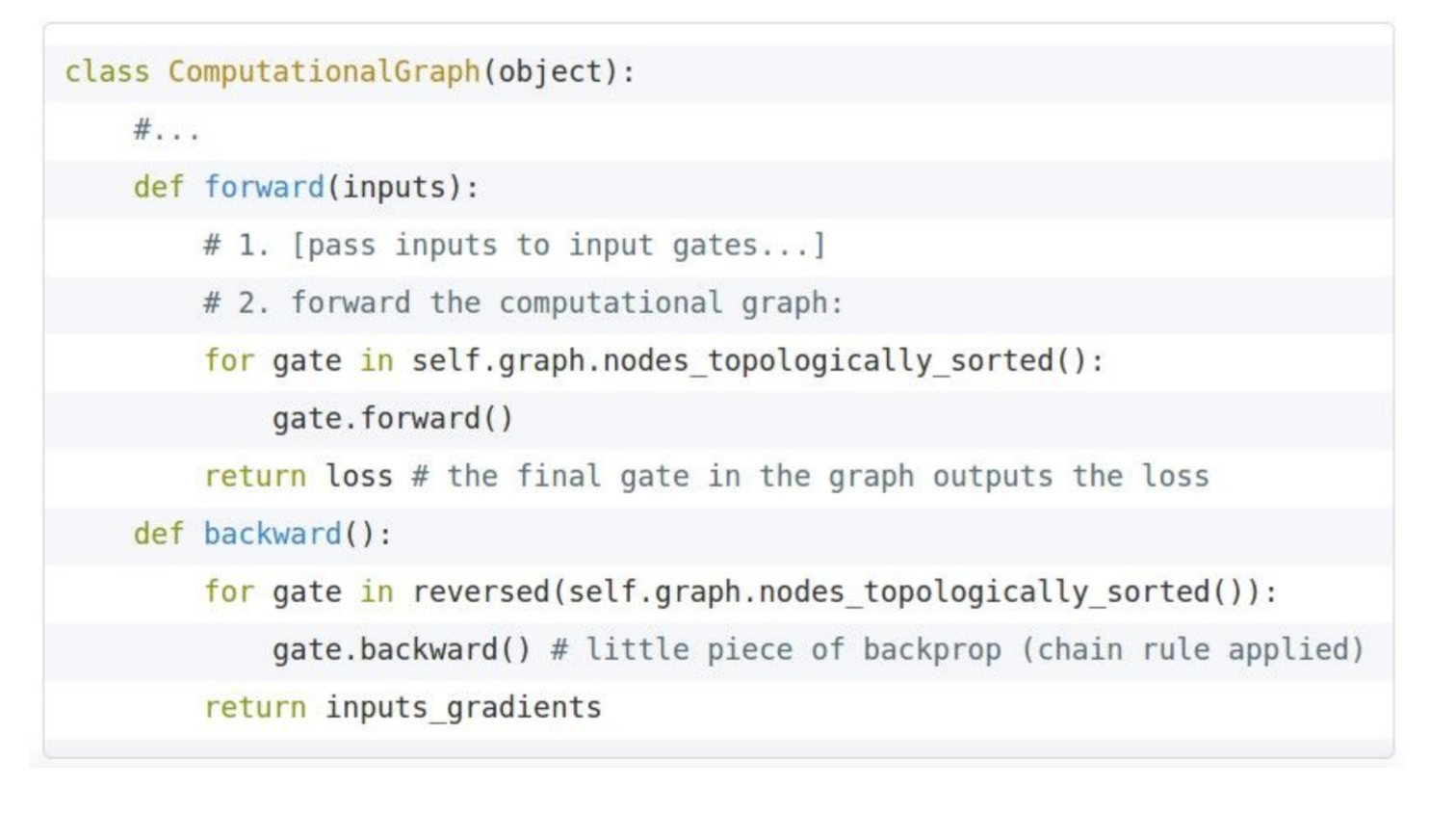
직관적으로 forward는 순전파, backward는 역전파를 뜻하는 것을 알 수 있다.
이렇게, NeuralNet과 Backpropagation에 대해 알아보았다. 전에도 알고 있던 내용이긴 했지만, 이렇게 자세하게 손으로 계산하는 것부터 소프트웨어적으로 다루는 법까지 배우게 되어 좋았다. 실습도 해보고 싶은데.. 우선 강의를 다 듣는 것이 먼저인 것 같아서 앞으로는 강의만 계속 정리할 생각이다.