[텍스트마이닝] 2-1. 텍스트 표현과 문서 유사도
텍스트마이닝 스터디 두 번째 주차에는 BoW와 N-gram, TF-IDF, Euclidian Distance와 Cosine Similarity 등에 관해 학습했다.
자세한 코드들은 깃허브 참고하길 바란다.
1. 텍스트를 숫자로 표현하는 방법
텍스틀을 숫자로 표현하는 방법에는 국소 표현과 연속 표현이 있다.
국소 표현에는 BoW, N-gram, One-hot Vector이 포함되며, 연속 표현에는 LSA, Word2Vec, Glove 등이 포함된다.
이 중, 국소 표현인 BoW에 대해 중점적으로 학습했다.
2. Bow
BoW란, Bag of Words의 약자로, 단어의 등장 순서를 고려하지 않는 빈도수 기반의 단어 표현 방법이다.
BoW는 다음 두 가지 특징을 지닌다:
- 각 단어에 고유한 정수 인덱스를 부여한다.
- 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터를 만든다.
다음과 같이 예시를 들어 보자:
text = '이해 쏙쏙 텍스트마이닝 정말 정말 재미있어요' 이라고 하자.
각 단어에 고유 정수 인덱스를 부여해보자:

Bag에 담고 각 인덱스의 위치에 단어 토큰의 등장 횟수를 작성하면 다음과 같다:
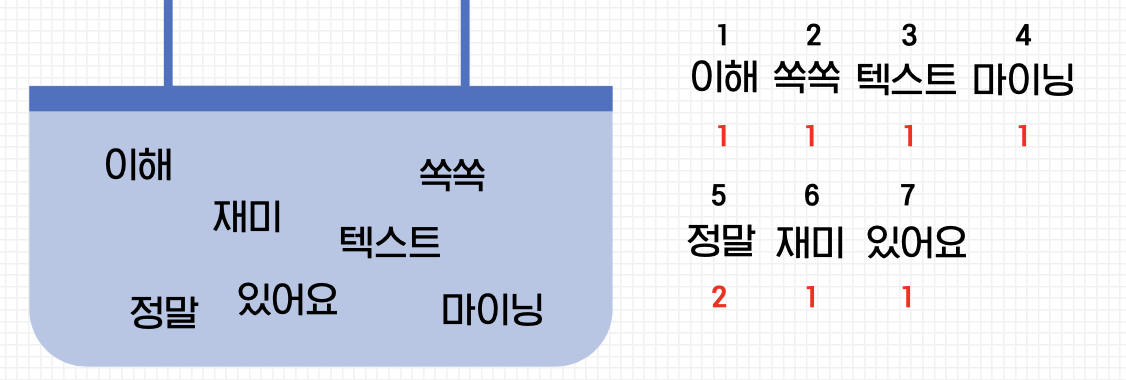
이렇게, 추출된 단어들로 다음과 같은 벡터를 만들 수 있다:

이러한 작업이 BoW를 만든 것이다.
이렇게 서로 다른 문서들의 BoW를 결합해서 만든 것을 DTM이라고 합니다.
3. DTM
문서 단어 행렬(Document-Term Matrix, DTM)이란 다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 표현한 것을 말한다.
쉽게 생각하면 각 문서에 대한 BoW를 하나의 행렬로 만든 것으로 생각할 수 있다.
다음과 같은 예를 들어보자:
- text1 : 먹고 싶은 사과
- text2 : 먹고 싶은 바나나
- text3 : 길고 노란 바나나 바나나
- text4 : 저는 과일이 좋아요
위 문장들을 띄어쓰기 단위로 토큰화를 진행하고, 문서 단어 행렬로 표현하면 다음과 같다:
| text1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| text2 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
| text3 | 0 | 1 | 1 | 0 | 2 | 0 | 0 | 0 | 0 |
| text4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
이렇게 각 문서에서 등장한 단어의 빈도를 행렬의 값으로 표기한다.
DTM은 문서들을 서로 비교할 수 있도록 수치화할 수 있다는 점에서 의의를 갖는다.
그러나 이런 DTM에도 문서에 많이 등장하는 단어가 비슷하면 두 문서가 유사하다는 결과가 나온다는 문제점이 있다. 이에 대해, 모든 문서에서 많이 등장하는 단어의 영향력을 줄이자는 해결방안이 나오게 되었다. 이 개념을 TF-IDF라고 한다.
4. TF-IDF
TF-IDF는 단어의 빈도와 역 문서 빈도를 사용하여 DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법이다. 이 방법은 주로 문서의 유사도를 구하는 작업, 검색 시스템에서 검색 결과의 중요도를 정하는 작업, 문서 내에서 특정 단어의 중요도를 구하는 작업 등에 쓰인다.
TF-IDF에서 TF란 Term Frequency의 약자로, 한 문서 내의 단어의 빈도를 뜻하고,
DF란 Document Frequency의 약자로, 오직 특정 단어 t가 등장한 문서의 수를 뜻하고,
IDF란 Inverse Document Frequency의 약자로, 어떤 단어가 등장한 문서의 빈도의 역수를 뜻한다.
IDF의 개념에 대해 살펴보자. 우선 식은 다음과 같다:
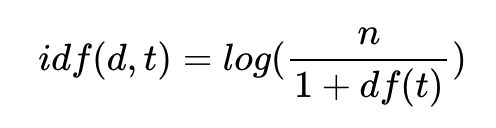
여기서 n은 총문서의 수이다.
이때 로그를 취해주는 이유는, n이 너무 커지게 될 경우, 값을 scaling 해주기 위해 사용하는 것이다.
이렇게 구한 tf와 idf를 곱한 값을 tf-idf라고 한다.

이렇게 BoW에 기반하여 DTM, TF-IDF처럼 단어를 수치화하는 방법에 대해 학습했다. 이렇게 수치화한 방법에 이어 문서의 유사도를 구해보자. 대표적으로 2가지 방법이 있다.
- 유클리디안 유사도
- 두 벡터의 거리가 가까울수록 유사하다.
- 코사인 유사도
- 두 벡터가 이루는 각도가 0에 가까울수록 유사하다.
여기서 코사인 유사도에 관해 설명하자면, 고등학교 때 벡터의 내적에서 사잇각을 구한 방식과 비슷하게 계산된다. 식은 다음과 같다:
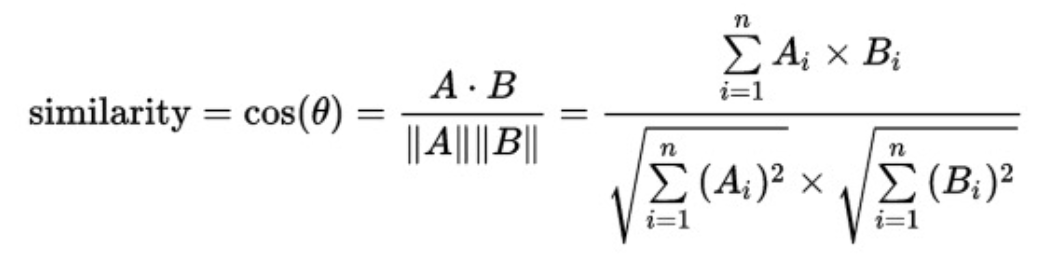
이렇게, 이번에 텍스트 내의 단어들을 숫자로 토큰화시키는 방식과, 해당 숫자들을 기반으로 유사도를 구하는 방식에 관해 간단하게 알아보았다.