
연구 분야를 정하려고 논문을 보고 있는데, NID (New Intent Classification) 논문들을 계속 읽게 된다.
본 논문은 2022 ACL 학회에 수록된 논문이며, 주 저자는 Yuwei Zhang 이다.
Abstract
Problem
기존의 방법들은 다량의 labeled data에 의존하거나 pseudo-labeling을 통한 clustering 방법을 사용하기 때문에 너무 label에 의존적이다.
본 연구에서는 NID 분야에 있어 다음 질문들에 대한 답을 얻고자 했다:
- 어떻게 의미적 발화 표현을 학습시킬 수 있는지
- 발화들을 어떻게 더 잘 clustering 할 지
Method
- Multi-task pre-training(MTP) 전략 사용
- representation learning을 위해 많은 양의 unlabeled data와 외부 labeled data를 함께 활용
- New Contrastive Loss (CL) 사용
- unlabeled data에서 clustering을 위해 self-supervisory signal을 만듦
해당 방법은 3가지 dataset으로 평가되며, unsupervised와 semi-supervised 방식 모두에서 SOTA를 달성했다.
Introduction
단어의 의미적 표현을 통해 clustering을 위한 좋은 근거를 전달하는 것이 중요함 → 그냥 PLM 이용해서 발화 표현을 생성하는건 솔루션이 될 수 없음
Recent Works
- labeled data를 사용한 이전의 연구들은 많은 양의 known intents와 충분한 양의 labeled data를 필요로 했음. → 그러나 이 상황은 실제 상황과는 거리가 멀음
- pseudo labeling 접근을 통해 supervision signal을 만들어 representation learning과 clustering 하려는 노력들도 있었지만, data들이 noisy하고 에러가 많았음
Solutions
- Multi-task pre-training (MTP) : 외부 (external) data와 내부 (internal) data를 함께 사용하여 representation learning 하는 방식
- 공개된 high-quality intent detection dataset과 현재 도메인의 labeled, unlabeled dataset을 모두 활용해서
- PLM 파인튜닝을 진행한 후,
- NID를 위한 task-specific 발화 표현을 학습함
- Contrastive learning with nearest neighbors (CL-NN) : 이웃 관계를 활용해서 unsupervised와 semi-supervised 시나리오 둘다에 contrastive loss를 적용하는 방식
- 의미적 공간에서의 이웃은 비슷한 intent를 보유할 것이고, 해당 샘플들을 모으면 cluster를 더욱 컴팩트하게 만들 수 있음
Related Works
NID
- unsupervised methods
- semi-supervised methods: using labeled data to support the discovery of unknown intents
- supervised methods: known intents에 대해 pre-train 한 후, k-means clustering 적용해서 unlabeled data에 pseudo label 할당
Pre-training
- pre-training with relevant tasks can be effective for intent recognition 라는 사전 연구
→ 본 논문에서는 공개적으로 이용 가능한 intent dataset + unlabeled data in current domain을 pre-training에 사용 → few-shot intent detection
Method
Problem Statement
- expected intent C_k
- known, labeled dataset / unlabeled dataset
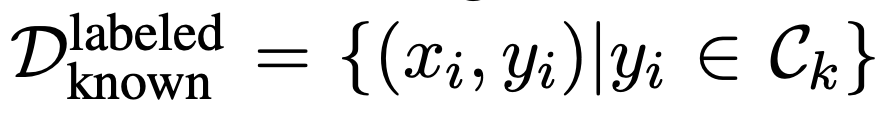

목적: unlabeled dataset의 unknown intents 찾아내는 것
본 논문에서는 unsupervised와 semi-supervised 2가지 모두의 방법을 사용함.
Overview
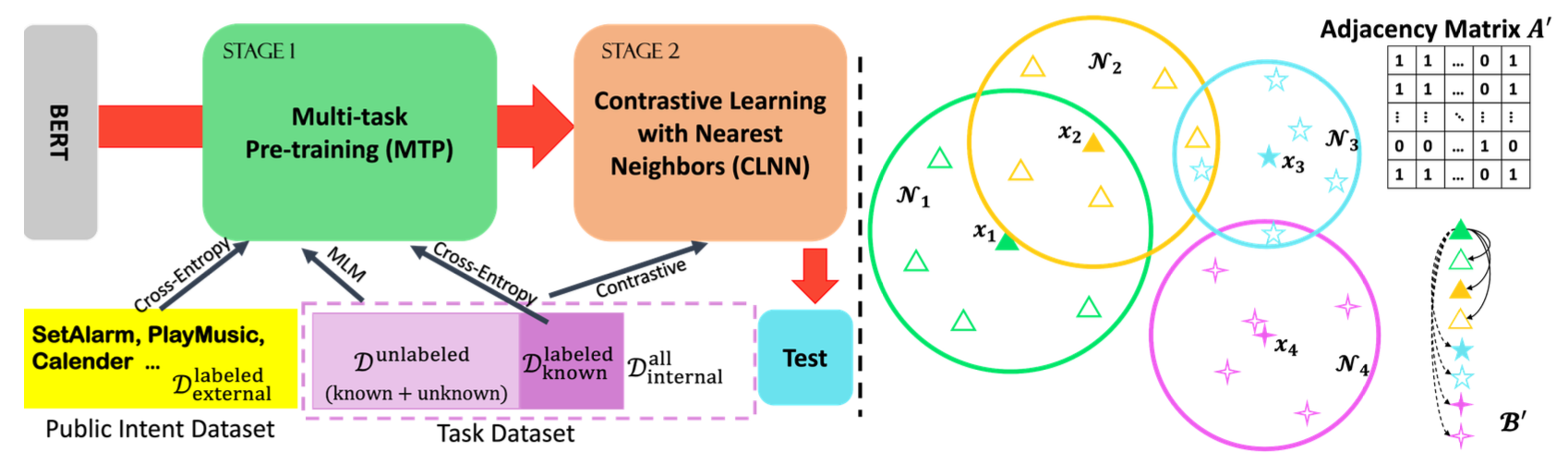
- MTP 단계
- 외부 (external) data에 대해서는 cross-entropy loss
- 내부 unlabeled data에 대해서는 self-supervised loss
- CLNN 단계
- top-K nearest neighbors를 embedding space에 표현
- 이후, contrastive learning with nearest neighbors 적용
- clustering algorithm → obtain clustering results
1. MTP
key method: pre-train을 위해 현재 domain의 labeled data가 아닌, 공개된 public data 사용
- pre-trained BERT encoder 사용
- joint pre-training loss

- 외부 labeled data에 대한 cross-entropy loss: 외부 labeled data는 다양한 도메인의 데이터를 사용
- 주로 classification task에서는 intent recognition의 일반적인 지식 얻으려는 것이 목적임
- 현재 도메인의 모든 데이터에 대한 MLM loss
- self-supervised task에서는 발화의 현재 도메인에서의 의미를 얻고자 함
-> 이후에 clustering task를 위한 의미적 발화 표현을 얻음
Semi-supervised NID
이후 semi-supervised 방식과의 비교를 위해서는 위 식에서 D-labeled-external을 (현재 도메인의 데이터인) D-labeled-known으로 바꾸면서 얻을 수 있음
2. CLNN
key method: 의미적 공간에서 이웃 instance들을 가깝게, 멀리 떨어진 instance들은 멀리 하면서 compact한 clustering이 가능하도록 함
- PTM으로 발화 encode
- 각 발화 x_i에 대해 top-KNN을 찾아 이웃 N_i를 형성함. (이때 distance metric으로는 inner product를 사용) - N_i에 속한 발화들은 x_i와 비슷한 intent를 공유해야 함
- 이때 neighborhood는 적당한 epoch마다 update됨!
- 발화의 minibatch 샘플링함

4. Beta에 속하는 x_i에 대해 N_i에서 하나의 원소 x_i’ 생성
5. data augmentation을 통해 x_i를 기반으로 \hat_{x_i}를, x_i’을 기반으로 \hat_{x_i}’ 생성 → 이들을 x_i의 positive pair들로 간주함
6. augmented batch 얻음

7. contrastive loss 계산을 위해 2M X 2M 크기의 binary matrix 만들어
-> 1: positive, 0: negative 나타내게 함
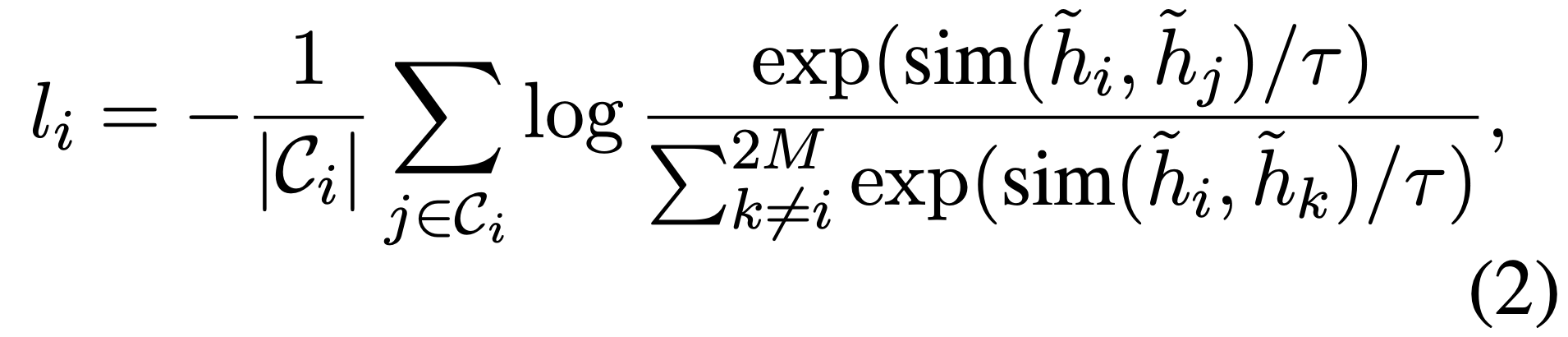

- C_i는 \hat_{x_i}와 positive 관계에 있는 instances의 집합, |C_i|는 집합의 개수
- \hat_{h_i}는 \hat_{x_i}의 embedding
- sim은 유사도 계산 function
Data Augmentation - RTR (Random Token Replacement)
augementation 기법으로는 Random Token Replacement를 사용함.
unlabeled data로부터 keyword 식별하는 것이 어려우므로 랜덤 토큰으로 적은 양의 토큰을 대체하는 것은 intent 의미를 바꾸지 않을 것임
Advantages of CLNN
- 비슷한 instance들은 가깝게, 다른 instance들은 멀리 위치시킴으로써 컴팩트한 cluster 생성 가능
- noisy한 pseudo label 쓰는거보다 embedding space에서의 실제 거리나 위치를 활용할 수 있음
- logit을 클러스터링 하는 대신 특성 공간에서 직접 최적화 → 더 효과적임
- 인접 행렬 (adjacency matrix)을 사용해서 known intents 자연스럽게 통합
Experiment
Details
Dataset

- CLINC150 - external public intent dataset: 10개의 domain으로 구성: 그중 8개만 사용하고 나머지 삭제
- dataset splittraining validation test
BANKING 9003 1000 3080 StackOverflow 18000 1000 1000 M-CID 1220 176 349
Setup
Unsupervised & Semi-Supervised 둘다 평가 - unsupervised로 평가 시에는 labeled data가 없는 채로 간주하고 실행
- KCR: proportion of known intents ratio
- KCR = 0: unsupervised NID
- KCR > 0: semi-supervised NID
- KCR = {25%, 50%, 75%}
- LAR: proportion of labeled examples for each known intent
- labeled data는 training data에서 랜덤하게 샘플링
- LAR = {10%, 50%}
Metric
NMI, ARI, ACC
Baselines

Implementation
- bert-base 모델 사용: CLS 토큰을 BERT representation으로 사용
- MTP
- external dataset에 대해 수렴할 때까지 train함
- labeled, known data train 할 때는 development set 사용해서 early stopping
- CL
- 768-d BERT embedding을 128-d 벡터로 사영: 2개 layer로 이루어진 MLP
- temperature: 0.07
- NN
- faiss (파시스) 를 nearest neighbor 찾는 inner product method로 사용
- neighbor size K 설정: K에 따른 각 데이터셋에 대한 스코어를 실험했을 때 가장 좋은 스코어를 보인 K들로 시작
- BANKING, M-CID는 50
- StackOverflow는 500
- neighborsms 5epoch마다 update

- data augmentation
- RTR 사용 - probability 0.25
- model optimization
- AdamW
Result Analysis
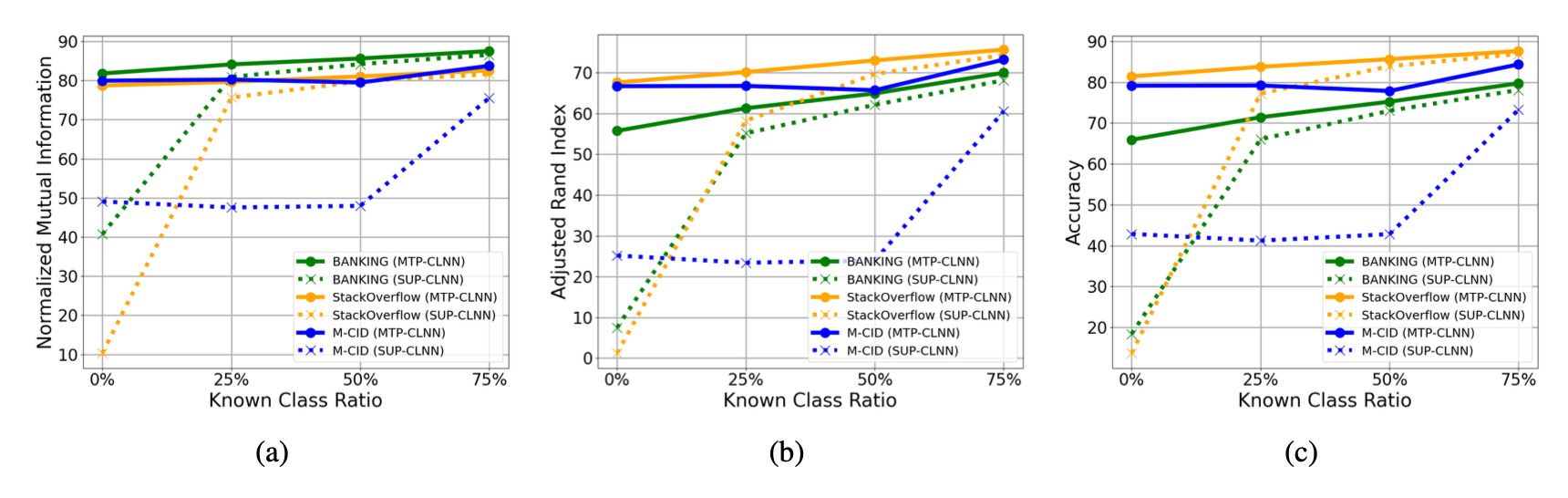
- Unsupervised에서 strongest baseline이었던 SAE-DCN보다 스코어 높음 → external public 데이터와 unlabeled internal utterance 둘다 사용하는거 좋다
- Semi-supervised에서 KCL이 75%일 때와 25%일 때를 비교하면 성능이 8.55%밖에 안떨어짐 → MTP를 사용하는 것이 labeled-class에 덜 의존적인 것을 보여줌: label-effective 함
- MTP-CLNN이 성능 제일 좋음
- Visualization: t-SNE로 visualization 한거 보면 MTP-CLNN이 제일 컴팩트하게 clustering 됨

Ablation Study
- Ablation Study on MTP
- MTP를 두 부분으로 분해할 수 있음
- PUB (supervised pre-training on external public data)
- MLM (self-supervised pre-training ong internal unlabeled data)
2. Ablation Study on neighborhood size K
- K에 따른 분포가 다르긴 하지만, MTP-CLNN > MTP 임
- Empirical (경험적) estimation method: 각 training set에 포함되는 각 class의 평균의 반을 초기 K로 설정
3. Exploration on Data Augmentation

RTR, SWR가 번갈아가면서 성능이 높은 것을 보임 - 간단하게 논문에서는 그냥 RTR만 씀
Conclusion & Limitations
Conclusion
MTP + CLNN 방법 썼음
Limitations
- balanced data에만 실험했음 - 실제와 비슷한 imbalanced data에 대한 실험도 필요함
- cluster에 대한 해석 능력이 부족함 - 각 unlabeled utterance에 cluster label을 할당할 수는 있지만 각 cluster에 대한 유효한 intent를 할당하기 어려움
'📚 논문' 카테고리의 다른 글
| Beyond Candidates: Adaptive Dialogue Agent Utilizing Persona and Knowledge (0) | 2024.01.06 |
|---|---|
| IDAS: Intent Discovery with Abstractive Summarization (2) | 2023.10.10 |
| Two Birds One Stone: Dynamic Ensemble for OOD Intent Classification (0) | 2023.08.28 |
| Discovering New Intents with Deep Aligned Clustering (0) | 2023.08.16 |
| A Probabilistic Framework for Discovering New Intents (0) | 2023.07.27 |